A global consumer goods company was facing acute business challenges such as delayed product recommendations, deferred billing and SLA non-compliance despite 1000+ node big data cluster. The firm had a storage of 23 petabytes of data with transaction tables as large as 90 TB, with billions of billing transactions that had to be traced while amending or cancelling any order. The 18-step discovery process with 20+ tables, that had to be joined, was becoming very inefficient. Furthermore, each business transaction was a multi-record transaction requiring time travel and backpropagation, and hence a complex match and merge logic.
This is a common challenge faced by global organizations wherein traditional data lakes fall short. What comes to the rescue in such a scenario is a Delta Lake integrated with a highly scalable and tuned cloud solution.
Architecting data pipeline with Delta Lake and Google Cloud
Delta Lake, an open source storage layer, incorporates ACID features in data lake, along with time travel, history tracking, metadata management, and governance. This collection of libraries and routines can leverage Amazon’s Simple Storage Service and Hadoop Distributed File System (HDFS) as default storage layer. Google Cloud Platform (GCP) can be used for the same. Figure 1 depicts how GCP and Delta Lake can be leveraged to build a unified data processing and consumption layer.
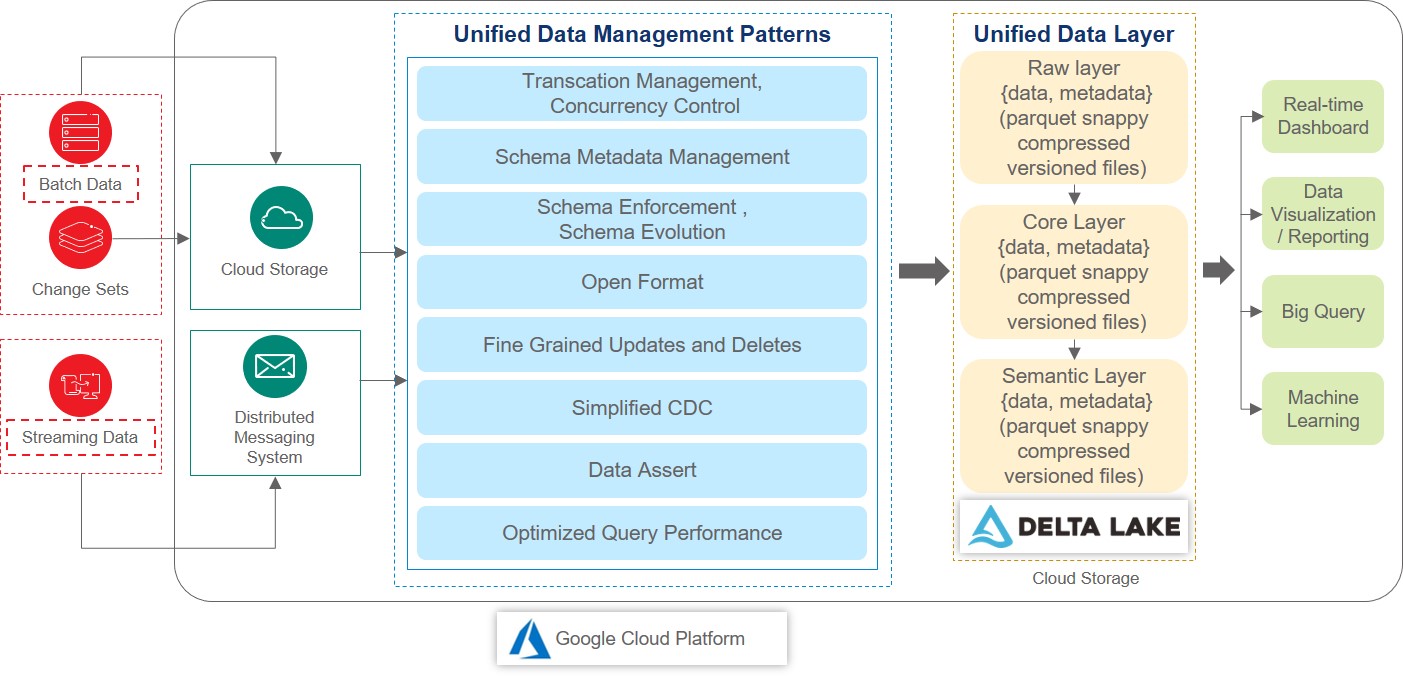
Figure 1: A unified data processing and consumption solution built on Google Cloud and Delta Lake
Creating single data narrative
The different layers of the unified data processing solution (Depicted in Figure 1) are
Data Sources: The source data for a typical billing schema consists of tables such as
Unified Data Platform Setup: Delta Lake leverages Spark framework for its processing. Google’s Dataproc comes with built-in Spark installation. It also has built-in Google Cloud Storage (GCS) connectors that reduce the deployment time considerably. Appropriate version of DataProc instance should be deployed and appropriate decencies should be added to pom file.
Unified Data Ingestion & Processing Layer: This layer can be developed using tools such as Google’s DataFlow or Delta enabled ETL tools like Talend
Unified Data Layer: The GCS buckets can be configured as storage layer for Delta Lake. The core business data gets stored in parquet format and logs will be maintained in json format. Further, to optimize query performance at this layer, data can be collocated using transaction-date based optimization and z-ordering on key fields such as order-codes/ cancellation-codes etc. This layer will be able to enable full ACID compliance with highly optimized querying / time travel on the data.
Unified Data Consumption Layer: Based on the nature of the data and access requirements, Google’s BigQuery and BigTables can be leveraged as the storage layer.
Effective data management
Organizations need actionable data. To fit the bill, data must provide a single version of the truth along with full governance capability. The enables decision makers to trust data and make insightful decisions. Delta Lake along with GCP provides an effective way to manage and control data.
Industry :

Rahul Sarda
Distinguished Member of Technical Staff at Wipro.
He has over 20 years of experience with deep technology and functional domain expertise. He has helped organizations across industry verticals develop value propositions for faster time to insights.
Ajinkya Chavan
Google Certified Professional Data Engineer.
He has over 18+ years of IT experience in the areas of analytics in architectural and consulting positions. His areas of expertise include Big Data, Cloud, DWH , ETL, Data Migration etc.







